Generative AI has traditionally been the domain of cloud providers and specialized AI infrastructure. Meanwhile, many research institutions and organizations have significant investments in High-Performance Computing (HPC) infrastructure that’s optimized for traditional scientific workloads or model training. A fascinating demo recently showed how these two worlds can be bridged, enabling organizations to run modern AI workloads on existing supercomputer infrastructure.
The Challenge
HPC infrastructure, particularly supercomputers, represent massive computational power that could be ideal for running large language models and other AI workloads. However, these systems are typically managed through batch scheduling systems like Slurm, which are fundamentally different from the container orchestration platforms like Kubernetes that modern AI infrastructure is built around (especially for inference).
A particular challenge is that Slurm environments traditionally offer limited access controls and user isolation – users typically all operate at the same privilege level within their allocation. This flat security model can be problematic when organizations want to provide AI services to multiple teams or departments with different security requirements, or even to the public as a cloud service akin to something like OpenAI or AWS Bedrock.
Solution
The demo showcases an integration between two key technologies:
- interlink: An open-source project that bridges Kubernetes and HPC infrastructure using virtual kubelet technology. It allows Kubernetes to schedule workloads onto Slurm clusters without requiring changes to the underlying HPC infrastructure.
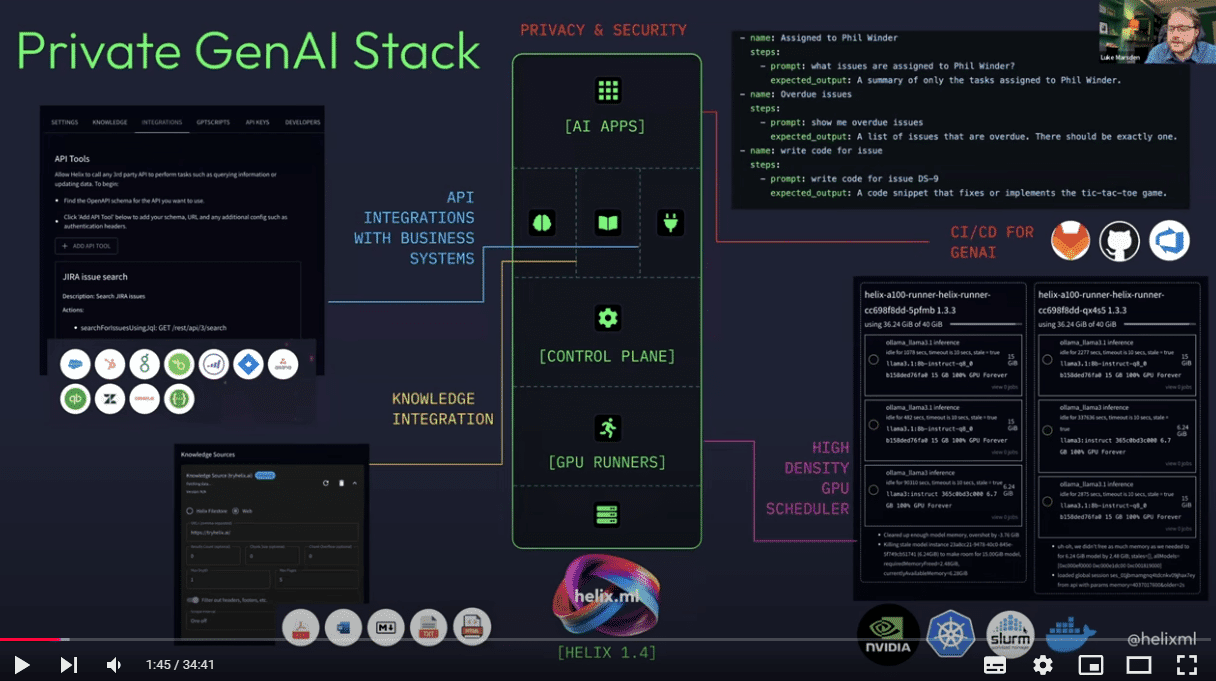
- HelixML: A private GenAI stack that provides ChatGPT-like capabilities but can run on local infrastructure. It includes features like:
- Multi-GPU scheduling and bin packing for LLM inference
- Support for modern open-source models (Llama3, Phi, Qwen, etc.)
- RAG (Retrieval Augmented Generation) capabilities
- API integrations to connect LLMs to business apps
- Version-controlled AI applications
- Automated testing for AI applications
- Enterprise-grade multi-tenancy and access controls
Technical Deep Dive
The integration works through several clever architectural decisions:
Multi-tenancy Layer
+
One of the most significant advantages of this integration is the ability to add proper multi-tenant isolation on top of Slurm’s traditionally flat security model:
- Authentication: HelixML provides KeyCloak integration, allowing organizations to use their existing Active Directory or LDAP systems for user authentication
- Resource Isolation: Different departments or teams can be given their own isolated environments with separate resource quotas, even though they’re all running on the same underlying Slurm infrastructure
- API Access Control: Fine-grained control over which users and teams can access specific models, knowledge bases, and API integrations
- Audit Logging: Comprehensive tracking of who is using what resources and how they’re being used
Virtual Nodes and Container Translation
+
Interlink uses virtual kubelet technology to make Slurm-managed resources appear as Kubernetes nodes. When pods are scheduled to these virtual nodes, Interlink translates the container specifications into Slurm job submissions. This translation layer maintains Kubernetes-native workflows while leveraging existing HPC infrastructure.
Shared File System Integration
+
The demo showed how the system leverages HPC shared file systems (typically NFS or Lustre) to cache large language model weights. This means multiple AI workloads can share the same model weights without duplicating multi-gigabyte files, significantly improving deployment efficiency.
Control Plane Architecture
+
The architecture separates the control plane (running in Kubernetes) from the compute plane (running on Slurm), connected via secure network connections. This allows organizations to:
- Keep authentication, multi-tenancy, and API management in modern container infrastructure
- Burst out to supercomputer GPUs for actual model inference and fine tuning
- Maintain existing HPC security and resource management policies
- Provide different teams their own isolated environments while sharing the underlying compute resources
Beyond Demos: Real-world Applications
The implications for scientific computing are significant:
1
Scientific AI Applications
Research institutions can build AI applications that integrate with their domain-specific APIs and knowledge bases while running on their existing HPC infrastructure.
2
DevOps for AI
The system supports modern development practices like:
- Version control for AI applications
- Automated testing of LLM behaviors
- CI/CD pipelines for AI deployments
3
Resource Efficiency
Organizations can leverage their existing GPU investments in supercomputers for new AI workloads without building separate infrastructure.
4
Enterprise Security
Organizations can provide AI capabilities to multiple teams while maintaining proper security boundaries and access controls, something that’s traditionally been challenging in HPC environments.
Looking Forward
This integration points to a future where the lines between traditional HPC and modern AI infrastructure continue to blur. As large language models grow in size and capability, the ability to run them efficiently on supercomputer-class infrastructure while maintaining proper security and multi-tenancy will become increasingly important.
The demo was performed on the Vega supercomputer in Slovenia as part of the Intertwin project, showing how these technologies can be applied to real-world scientific computing environments.
Get Started
Both Interlink and HelixML are available for organizations looking to explore running GenAI workloads on their HPC infrastructure. The integration requires minimal changes to existing supercomputer setups, primarily needing just a container runtime like Apptainer or Enroot on the compute nodes.
This integration represents a significant step forward in making advanced AI capabilities accessible to organizations with existing HPC investments, potentially accelerating scientific discovery through the combination of traditional supercomputing and modern AI techniques. The ability to add proper multi-tenant isolation on top of traditional HPC infrastructure is particularly valuable for organizations looking to provide AI services across multiple teams or departments.
Watch Demo
Watch a live technical demo of deploying modern AI infrastructure on HPC systems. See how HelixML and Interlink work together to run LLMs like Llama3 on the Vega supercomputer in Slovenia, complete with multi-tenant isolation, automated testing, and API integrations. Perfect for HPC admins, ML engineers, and anyone interested in running private AI infrastructure. In this demo:
- Deploy ChatGPT-like capabilities on Slurm clusters
- Run open source LLMs on supercomputer GPUs
- Add multi-tenant security to HPC infrastructure
- Build and test AI applications with version control
- Integrate external APIs with LLM applications
Featuring Luke Marsden (HelixML) and Diego Ciangottini from INFN demonstrating how to bridge the gap between traditional HPC and modern AI infrastructure.
Related Results

KER 2 – Interoperability Framework: Guidelines, Specifications, and Blueprint Architecture
Aligns technical approaches and foster collaboration in modelling and simulation application development across scientific domains.

KER 6 – interTwin Open Source Community
The community of DT application developers, users and operators that is responsible for the design,
